

As highlighted in a previous post:
One needs to stop thinking about Storage, to solve a Data problem.
But how is this even possible?
Data problems are solved by software implementing Data Services, and until now Data Services have been tightly coupled with Storage solutions. In most cases, if not all, Data Services comprise a significant part of the solution itself. This is why Storage products are targeted to different use cases, based on the specific Data Services they promote.
In this article, we discuss traditional Data Services, the current storage model they are based upon, and explain why this model limits the ability to provide a new breed of intelligent Data Services.
Why a new breed of Data Services?
IT teams need to operate in a world of heterogeneous and distributed IT infrastructure. Environments with on-prem and cloud deployments, dispersed locations that span the globe, distinct administrative domains, cloud-native applications and heterogeneous virtualization and container platforms. Data Services need to deliver data to the right place, at the right time and in the right form, independently of where and how it is persisted.
We argue that the industry needs to address the requirements for Data Services in a way that is decoupled from architectures that deal with physical storage management and data persistence. We propose a new model, where data management spans the traditional boundaries of IT infrastructure.
But first things first. Before we go there, let’s start from the beginning and see what we mean with traditional Data Services, how Storage has evolved, and what the current state-of-the-art is.
Traditional Data Services
Today, Data Services are typically added functions provided by a traditional Storage solution alongside data persistence. They aim to increase protection, efficiency, performance, to provide insights, and to ease integration with higher-level platforms (e.g., a cloud orchestrator). Most Data Services fall under the following categories:
Protection
- Backups
- Synchronous Replication
- Asynchronous Replication
- Archival
Efficiency
- Thin Provisioning (clones/snapshots)
- Storage Pooling
- Data Migration
- Deduplication/Compression
Performance
- Caching
- Tiering
- Random Write Acceleration
- Quality of Service (QoS)
Insights
- Data Analysis
- Reporting
- Monitoring
Integration
- Presentation of multiple I/O interfaces (block, file, object)
- Management APIs
Most industry storage products offer a custom data persistence scheme, coupled with a subset of the above Data services, depending on the use cases they are targeting. Many times, and due to physical or architectural constraints, some of the above Data Services may be inefficient or even mutually exclusive.
In any case, it’s safe to say that most modern storage solutions come with a
fair number of the above Data Services bundled with the core storage product. Data Services have evolved in parallel with the storage solutions, but their evolution has been rather slow and narrow, since they have been strongly coupled and affected by the evolution of persistent storage technology.
Storage evolution
Traditionally, storage has been one of the main pain points in Data Center management. A problem really hard to tackle, requiring subject matter expertise, sensitive to changes, and thus very slow in its evolution. After abandoning local, direct-attached storage in the 90s for the enterprise readiness and features of shared storage (Storage Area Networks), the ladder of evolution seems to have only three major steps:
1. Hardware Storage Appliances
HW Appliances are the traditional approach to shared storage and the one still dominating the enterprise market. These combine proprietary hardware with proprietary storage software running on top of it. The storage software stack undertakes the persistence of data on the physical devices and also provides the traditional Data Services for availability, performance and efficiency. Data Services apply only to the specific appliance and operate inside its context, or in the best case with a compatible appliance of the same vendor. This is the first step of evolution with all traditional vendors included in this category, e.g., EMC, NetApp, IBM, HP, Dell, Fujitsu.
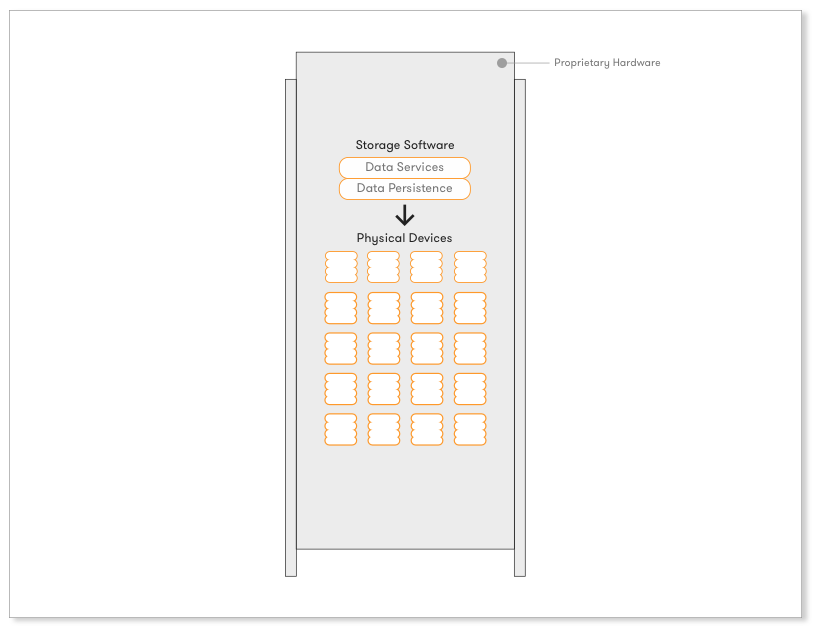
2. Scale-out HW Storage Appliances
Since HW Appliances were very difficult and expensive to scale as the needs of an organization grew up, the next step of evolution came with solutions that can stack up proprietary hardware appliances of the same type. Vendors produce proprietary hardware with proprietary software running on top, although this time the proprietary storage software stack is intelligent enough to operate uniformly as one expanded the infrastructure with more appliances. The software stack became distributed and abstractions were introduced to facilitate this change. However, although one could now scale up more easily, vendor lock-in, incompatibility across solutions and significant TCO still prevailed. Solutions like EMC Isilon, IBM SONAS, or NetApp’s ONTAP GX are indicative of this category.
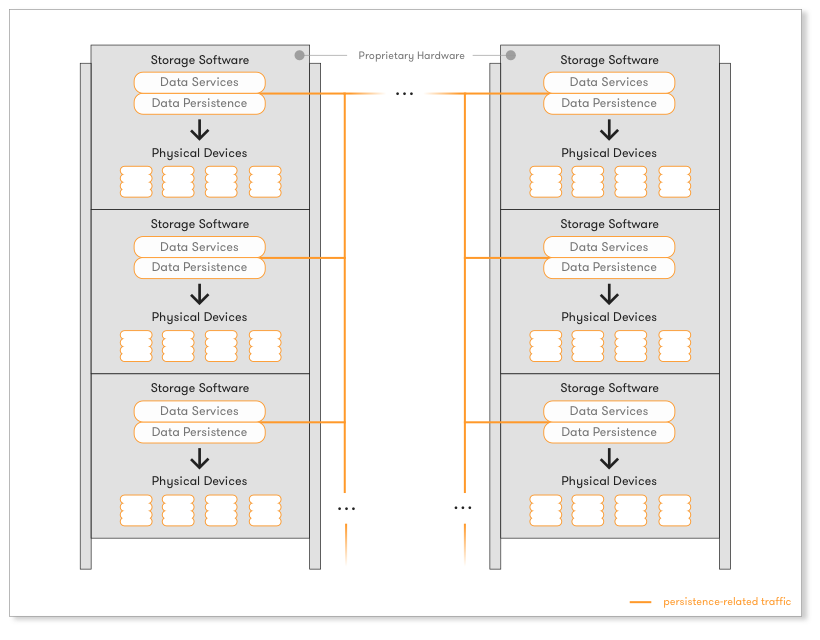
3. Scale-out SW Storage Appliances for commodity HW
Once the storage software stack could scale-out and operate while adding or removing new hardware, the next logical step followed, and this is where the state-of-the-art is today: decoupling the whole storage software stack from the proprietary hardware it runs on. Having the storage software as an independent entity, allows the industry and clients to run it on commodity, x86, off-the-shelf hardware, paired with all the latest performant devices (flash, SSDs, NVMe) in a multitude of setups. This is where the industry is heading today. Cost savings are massive and the client does not get locked-in on the hardware side, anymore.
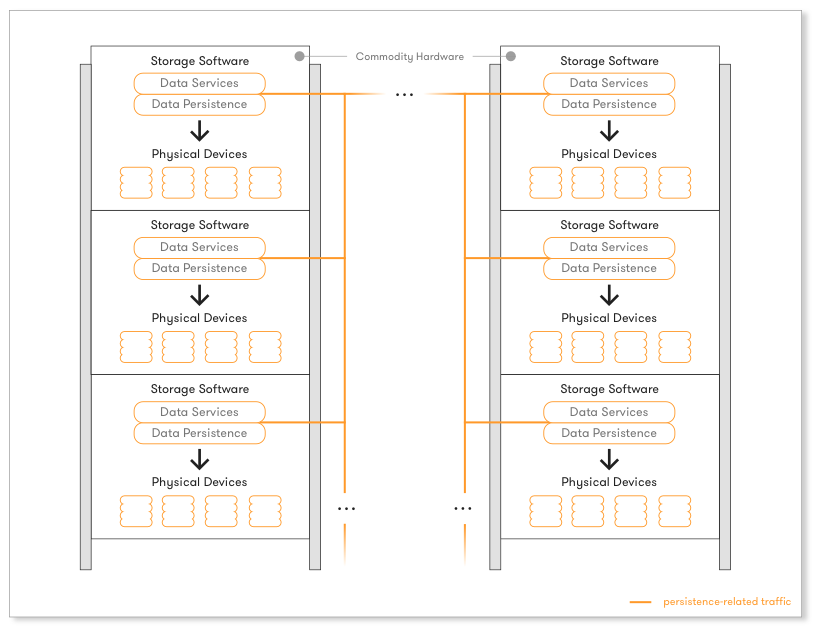
The utilization of commodity x86-based server platforms for both compute and storage led to the so-called converged hardware model. The most purist form of this model is hyper-converged infrastructure (HCI), where the storage software stack runs on the same hardware as the application workloads. The cookie-cutter model of data center architecture has many benefits in terms of simplicity of procurement, configuration and management of IT infrastructure. Examples in this category include VMware VSAN, EMC ScaleIO, Red Hat Ceph, Nexenta, Springpath.
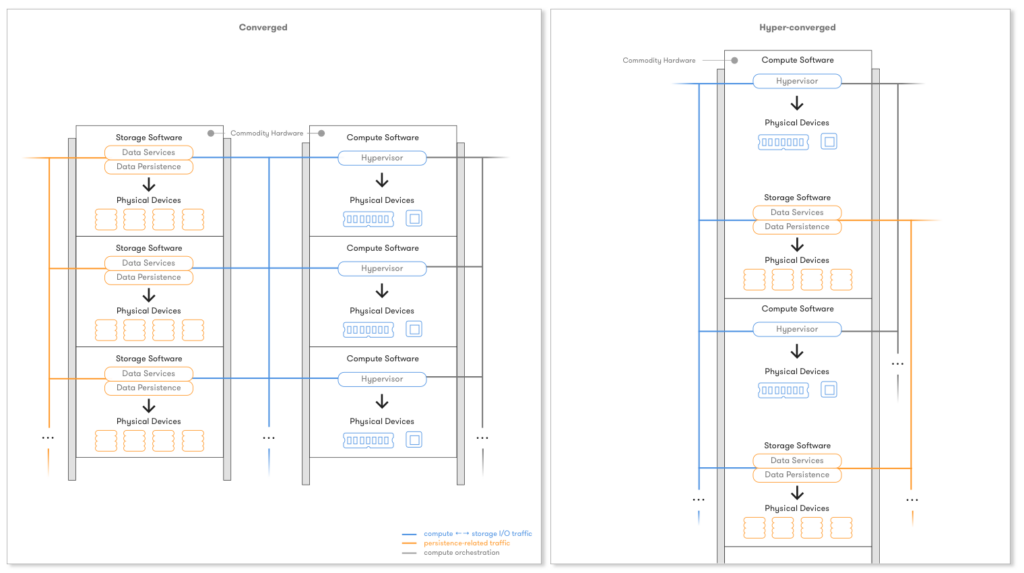
Although progress has been made moving to software-only solutions that run on commodity hardware, the model of a software stack that implements both persistence and Data Services is incapable to address todays challenges.
Current challenges
In a world of on-prem and cloud infrastructure, dispersed locations, distinct administrative domains, cloud-native applications and heterogeneous virtualization and container platforms, having storage in software, even if it scales-out well and runs over commodity hardware, doesn’t solve today’s challenges.
Enterprises need to be able to move data around, back and forth, from on-prem to the cloud and from legacy storage systems to new ones. They need to be able to consume the same data for different purposes and thus from completely different applications, which may run on different platforms or physical servers. All storage management related operations, both on the data and control plane, need to become uniformly programmable over APIs across all these heterogeneous environments. This should happen independently of where the data gets persisted, if one wants to streamline procedures.
Even with the most advanced storage solutions, currently the execution context of customer workloads is confined within the physical boundaries and properties of the storage system where the application’s data is provisioned. Even when feasible, data mobility involves separate workflows (e.g., VMware’s Storage vMotion or EMC’s Recover Point), expensive manual data migrations and transformations. This happens because intelligence, mobility, protection and transformation functionality, implemented by Data Services, is still strongly coupled with the specific storage products that implement data persistence.
A very common example that showcases this problem is Snapshots.
Assume for a moment that one has a very good solution that is able to do very fast, thin Snapshots of their data for, let’s say, backup purposes. When a selection of these Snapshots needs to get archived, the archival solution uses its own type of Snapshots, so the previously intelligent and thin Snapshots need to get converted ceasing to be thin and intelligent after all. And what happens when these Snapshots want to get used by a different solution for disaster recovery? Or even worse, what happens when their owner wants to move them to the cloud? New conversions, transformations, exports and imports need to take place, since every different storage solution in the pipeline has a different Data Service implementing Snapshots.
Tight coupling of Data Services with the storage persistence logic can be clearly witnessed on the above figures on all steps of the Storage evolution and has not changed a bit, while storage software has been evolving.
Decoupling of the Storage Stack
Most of the industry focuses on solving the above problems by advancing storage products, putting more intelligence into them, and competing on whether those storage products are software-only or not, on commodity hardware-based or not, hyper-converged or converged.
We believe that the next step of true evolution is the decoupling of the storage software stack itself. The multitude of storage solutions and the diversity of data management needs in today’s IT environments dictates the decoupling of Data Services from the persistence logic and its operations. IT teams require Data Services that function regardless of where the data is actually persisted and appear in a unified and transparent way on the different platforms that consume the data, independently of their type and location.
We need independent Data Services that will operate on a global scale and on top of any persistent data store, without caring how the data gets persisted.
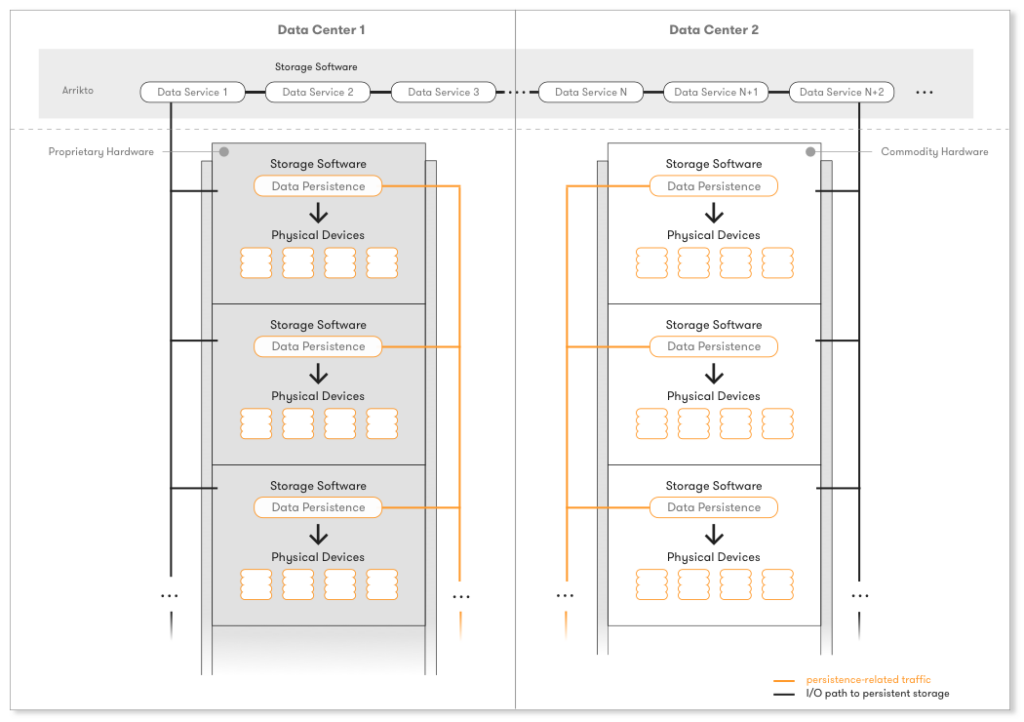
Until now, the industry looked at Data Services from the ground up, with persistence in mind, and that’s why Storage companies were the only ones dealing with their implementation. Assuming that persisting data in a distributed and scale-out way, over commodity hardware, is a problem efficiently addressed today by current Storage solutions, we argue that once the storage software stack gets decoupled and Data Services become independent, a whole new world opens up. One is now able to look at Data Services top-to-bottom, from the virtualization/container platform or even application perspective.
A new breed of independent Data Services
Looking at independent Data Services top-to-bottom, and being able to operate on top of any persistent storage solution, opens up a multitude of options to solve today’s intriguing problems.
On our previous example, we can now have an independent Data Service that implements thin Snapshots across all the different persistent technologies chosen regarding the use case’s characteristics. These Snapshots, although thin, are by definition common for the Backup, Archival and DR solutions, and are transparently transferable from one persistence technology to the other. If the Data Service is intelligent enough and provides the appropriate APIs, these Snapshots will be consumable from different higher-level platforms or applications too. Expand this to multiple locations, and now things start to get really interesting.
The need is already here and with independent Data Services the solution is closer than ever. Problems that once seemed untouchable, become instantly addressable. This new breed of intelligent Data Services will introduce functionality that was never there before, truly aligned with today’s higher-level requirements. It will transform the day-to-day procedures of users, developers and administrators, putting a whole new toolset in their hands, while freeing them from today’s unnecessary burden of handling and constant thinking about storage.
At Arrikto, we are actively working in this direction. We recognize the opportunities of independent Data Services in modern IT environments and we are delivering innovative products to meet the evolving needs of IT organizations, developers, and end-users. Meet us at VMworld US 2016, and get the first glimpse of what we are working on!
Update: Check out our Rok Data Management Platform and Enterprise Kubeflow solutions!
Company names, product names and other marks mentioned herein may be trademarks or registered trademarks of their respective companies.