

At this year’s KubeCon + CloudNativeCon North America 2021 I had the pleasure of co-presenting a keynote with Masoud Mirmomeni, Lead Data Scientist at Shell. In this blog post I’ll recap the talk for those of you who may have missed it.
tl;dr
- Kubeflow makes machine learning easier at Shell by closing the gap between data science and operations.
- Kubeflow creates an efficient platform for Shell’s data scientists, so they can collaborate, share ideas, and inherit from each others projects easily from laptop to production
- Kubeflow reduces the cost of model building at Shell by managing the required computational resources efficiently
What does machine learning have to do with Kubernetes?

To set the stage for Shell’s portion of the talk, it doesn’t hurt to spend a minute detailing why machine learning and Kubernetes are a match made in heaven.
First, containers allow us to create, test and experiment with machine learning models on our laptops, and at the same time we know that we can take these models to production with containers. The idea here is not new, we want to write once, reproduce and run everywhere.
Second, a machine learning workflow on our laptop may be written entirely in one language, like Python. But perhaps in production we’ll need to interact with different applications to handle things like data, security or front-end visualizations. In these scenarios a microservices-based container architecture will be invaluable.
Finally, machine learning loves GPUs. But GPUs are expensive. So, it’s not always about how fast we can provision and scale-out to obtain all the resources we need, but it can be just as important how quickly we can spin the deployment back down to zero. Here again, containers are a perfect fit.
Why do many machine learning models fail to make it to production?

Among the many trends happening in IT right now, there are two big ones that are strategic imperatives at just about every Fortune 1000 company. The first one is going to be the adoption of cloud native architectures. I think we can all agree that Kubernetes is everywhere and its adoption is only increasing for the foreseeable future. Second, the widespread adoption of AI, data science and machine learning initiatives at “traditional” enterprises that we often don’t think about as being at the vanguard of big trends in IT. In this case, the most innovative and transformative insights in regards to machine learning are indeed happening at “big” companies in “boring” businesses like automobile manufacturing, healthcare, insurance, financial services, mining and yes, oil and gas exploration.
Unfortunately, the open secret in the industry is that many machine learning models are failing to make it to production. Why is this? This is often a combination of factors including skills, software, methodology and the ability to efficiently collaborate. With technology and organizational structures at big companies being what they are, it is often very challenging to work “together”. However these enterprises experience friction because Data Scientists are expected to be Kubernetes experts and vice versa. The expectations on the roles are not consistent with the skills of the person hired into the role! And by skills we mean that we are often asking data scientists to be Kubernetes experts and Kubernetes experts to be data scientists. Therefore finding the software, methodology and perhaps the empathy that will be needed to ensure success can be a bit elusive. So, what are we to do?
Machine Learning + Kubernetes = Kubeflow

Enter Kubeflow. Kubeflow is the open source project smack dab in the middle of this “big convergence” in IT. Kubeflow was originally launched by Google back in 2017 and has since become the most robust, open source, cloud native by design (not as an afterthought) machine learning platform for data scientists AND operations folks. It’s a complete toolkit of components that allow BOTH data scientists and operators to manage data, train models, tune and serve them as well as monitor them. Kubeflow is facilitating the convergence of cloud native architecture and the machine learning community.
At this point in the talk Masoud took over and walked us through part of Shell’s data science and machine learning journey so we could understand how they leveraged Kubeflow and its ecosystem of integrations to solve many of the challenges that they were facing.
Shell’s focus on green and renewable energy is driving its use of AI
Most of us might think of Shell as an oil giant, however, in recent years Shell has expanded its focus to green and renewable energy as alternative sources of power.
In fact, it has allocated up to $2 billion annually to this effort and is expected to invest even more in the years ahead. These investments have included solar farms, wind generation facilities, energy storage, and even smart metering. When operating in such a dynamic environment, which includes moving electrical power from generation sources to customers (with volatile consumption patterns), the system is going to demand the deployment of a smart, quick and agile control network. It was quickly realized that this could only be achieved by leveraging artificial Intelligence at a massive scale.
Obviously, when AI is deployed at scale you are going to encounter some challenges. In the next section we’ll look at a few of them in detail.
Challenges that delayed obtaining value from data science investments

In this portion of the talk, Masoud detailed three challenges that were crippling Shell’s ability to get the desired return on investment from their data science initiatives.
Disparate and inconsistent development environments
If you’ve ever worked on a data science team, you know that folks are passionate about doing pattern discovery, working with data and predicting behaviors with machine learning. Data exploration, model building, model validation, and statistical analysis, these are the things that excite a data scientist.
What doesn’t excite them? Typically, they find little joy in setting up development environments, installing packages and fixing the inevitable incompatibilities between them. And of course, there is the whole issue of obtaining enough computational power and memory to efficiently run their tests and experiments. At Shell, setting up such environments at scale could easily consume days or even weeks before data scientists were even able to start building models
Too many specialized infrastructure skills required
The second challenge was the complexity of setting up scalable machine learning infrastructure. While it is a rather trivial exercise to set up a Jupyter notebook on your laptop and write some machine learning code that trains a basic model with a small data set, the process becomes a lot more complex when scaling up to a production-grade system. It even gets more complex when you want to set up a rich production grade notebook that can run on any infrastructure.
So, while it is a no brainer that data scientists will want to run their machine learning projects on Kubernetes to take advantage of the portability and scalability it offers, expecting them to be experts in Containers, Kubernetes, storage, horizontal scaling, GPUs and a whole lot more is not realistic.
Wasted and underutilized resources
In the third challenge Masoud outlined, Shell wanted to make sure they could leverage all the data they had at their disposal when training their models, but to do so without bankrupting their IT department. It was unrealistic for Shell to provide every data scientist with their own GPU. Besides that, as we all know, model training is very spiky when it comes to resource consumption. In the development phase the team may only need 1 or 2 GPUs. But during the training phase they may need many more resources to finish in a reasonable time frame. Finally, when compute resources sat idle, Shell lost money. When data scientists waited long hours for their models to be trained, Shell also lost money.
So, what was the solution to the above problems?
How Kubeflow accelerated the data science lifecycle at a much lower cost

In this portion of the talk, Masoud detailed three ways that Kubeflow helped Shell overcome the challenges previously detailed.
Secure cloud hosting + Self-service
By adopting Kubeflow as its MLOps platform, Shell was able to switch to a self-serving model. This meant that pre-configured Notebook servers could be hosted in secured cloud environments. With these images readily available, it allowed data scientists to easily spin up new Notebook servers with all the compute and storage resources they needed for their training projects.
Also, with just a few clicks, they could also pick from several pre-configured machine learning development environments and toolkits that suited their particular needs.
With Kubeflow, a task that would take several days or even weeks, was available to them in just a few minutes.
Benefit: Rapid onboarding and productivity at scale
Automation, automation, automation (with Kale)
With the addition of the Kubeflow Automated PipeLines Engine (Kale), Shell’s data scientists could now easily create production-ready Kubeflow pipelines and share them with the operations team with just a few clicks or decorations. With Kale, Shell has been able to significantly reduce the complexity of pushing machine learning code that runs equally well on a laptop or a production environment.
Kubeflow Benefit: Easily turn Notebook code into scalable production pipelines
Shared cloud resources
Finally, by running their training jobs on Kubernetes, Shell’s data science team was able to easily share compute resources amongst themselves. Recall that in an ideal setup, expensive resources are only used when they are required and returned to the pool when the jobs complete. With the Rok data management add-on for Kubeflow, Shell can now monitor how Notebook servers are using cloud resources and take a snapshot of notebook servers that are sitting idle for more than 24 hours. They can then release the attached resources and make them available to other team members and workloads. With the added bonus that data scientists can spin up a new notebook server from those snapshots and start their work right from where they left off.
Kubeflow Benefit: Hyper efficient use of expensive resources
Case Study: How fully automated pipelines speed up model training time
Using the execution graphic below, Masoud next walked us though a real world scenario he encountered at Shell to illustrate how Kubeflow radically simplified the machine learning effort.
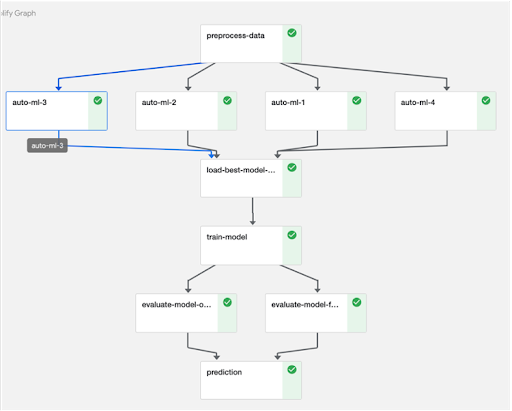
“ When I joined the data science team at Shell, my first assignment was to build a predictive model for a time series application. I had to load the data onto my local machine, sample it to reduce the runtime, and try different model configurations. Long story short, it took me two months to come up with a proper model in a Notebook format.
At that point I passed my code to one of our machine learning operations engineers so they could put the model in production. After two weeks my colleague came back and said I cannot reproduce your results!” To that complaint I responded in a way that I loathed to hear from my junior programming students when I was teaching computer programming 232. I replied “But it worked on my laptop.” Anyway after a couple of back and forths we could finally deploy the model. But the performance was terrible! It took us another month to figure out the critical missing step that my colleague did not consider in their implementation. It was not my colleague’s fault. I knew my code by heart, and it was wrong to assume that my coworker would understand my code in the same way.
Luckily, at the same time I was becoming acquainted with both Arrikto and Kubeflow. Using the tools provided by Arrikto, and with the help of one of my team members, we started building a machine learning discipline. I was soon able to reproduce the same results for another application from model training to model deployment in just 35 days…which in my second attempt was reduced to just a couple of days! Fast forward, some team members (who possess just basic programming skills) can now easily apply cutting edge statistical machine learning frameworks and deep learning to their projects in less than an hour with the help of Kubeflow components! “
Want to learn more about Shell’s machine learning journey with Kubeflow? Check out the keynote in its entirety..
Book a FREE Kubeflow and MLOps workshop
This FREE virtual workshop is designed with data scientists, machine learning developers, DevOps engineers and infrastructure operators in mind. The workshop covers basic and advanced topics related to Kubeflow, MiniKF, Rok, Katib and KFServing. In the workshop you’ll gain a solid understanding of how these components can work together to help you bring machine learning models to production faster. Click to schedule a workshop for your team.
Announcing Arrikto Academy
I should also point out that the “Kubeflow Fundamentals” courses are a feeder for the more advanced offerings of “Arrikto Academy”, Arrikto’s new skills-based Kubeflow education initiative. If you’d like to explore additional training options aimed at intermediate to advanced users of Kubeflow, check out Arrikto Academy! (You can also read the announcement blog here.)
In fact, we’ve recently released our first two courses – Kale 101 and Katib 101 – both of which focus on the necessary Day 1 Fundamentals that all data scientists need to be successful with the Kubeflow ecosystem. The courses are capped off with self-graded labs to ensure skills are being developed and retained.
About Arrikto
At Arrikto, we are active members of the Kubeflow community having made significant contributions to the latest 1.4 release. Our projects/products include:
- Kubeflow as a Service is the easiest way to get started with Kubeflow in minutes! It comes with a Free 7-day trial (no credit card required).
- Enterprise Kubeflow (EKF) is a complete machine learning operations platform that simplifies, accelerates, and secures the machine learning model development life cycle with Kubeflow.
- Rok is a data management solution for Kubeflow. Rok’s built-in Kubeflow integration simplifies operations and increases performance, while enabling data versioning, packaging, and secure sharing across teams and cloud boundaries.
- Kale, a workflow tool for Kubeflow, which orchestrates all of Kubeflow’s components seamlessly.