

We recently hosted the fifth delivery of the “Intro to Kubeflow: Fundamentals Training and Certification prep course. In this blog post we’ll recap some highlights from the class plus give a summary of the Q&A. Ok, let’s dig in!
Congratulations to Augusto Gentile!
The first student to earn the “Fundamentals” certificate at the conclusion of the course was Augusto Gentile who works at COREBI. A free MiniKF hoodie and shirt is on the way, well done!
First, thanks for voting for your favorite charity!

Arrikto is looking for even more ways to contribute. With this in mind, we thought that in lieu of swag we could give course attendees the opportunity to vote for their favorite charity and help guide our monthly donation to charitable causes. The charity that won this workshop’s voting was Every Mother Counts (EMC). The Every Mother Counts is a non-profit organization dedicated to making pregnancy and childbirth safe for every mother. They inform, engage, and mobilize new audiences to take actions and raise funds that support maternal health programs around the world. We are pleased to be making a donation of $100 to them on behalf of the Kubeflow community. Again, thanks to all of you who attended and voted!
What topics were covered in the course?
This initial course aimed to get data scientists and DevOps engineers with little or no experience familiar with the fundamentals of how Kubeflow works.
- Kubeflow architecture
- Overview of machine learning workflows
- Kubeflow components
- Tools and add-ons (Kale, Rok, Istio, etc)
- Distributions
- Installing Kubeflow on AWS
- Community overview
What did I miss?
Here’s a short teaser from the 90 minute training. In this video we demonstrate three things in regards to Katib (which is a Kubeflow component that provides AutoML, hyperparameter tuning and early stopping):
- How to view an experiment
- How to set up experiments
- How to identify the best run
Missed the Jun 1 Kubeflow Fundamentals training?
If you were unable to join us last week, but would still like to attend a future training, the next “Kubeflow Fundamentals” training is happening on July 14. You can sign up for this and the upcoming Notebooks, Pipelines and Kale/Katib courses here.
NEW: Advanced Kubeflow, Kubernetes, Distributed Training and Notebooks & Pipelines Workshops

- Jun 8: Kaggle’s Digit Recognizer Competition – Computer Vision Example
- Jun 9: From Kubernetes to Kubeflow Workshop
- Jun 15: Training course: Jupyter Notebooks Fundamentals
- Jun 16: Kaggle’s Titanic Disaster Machine Learning Example
- Jun 22: Kaggle’s House Prices – Advanced Regression Techniques Competition
- Jun 23: Kaggle’s Udacity Dog Breed Classification Example
Arrikto Academy
Are you ready to put what you’ve learned into practice with hands-on labs? Then check out Arrikto Academy! On this site you’ll find a variety of FREE skills-building labs and tutorials including:
- Kubeflow Use Cases – Kaggle OpenVaccine, Kaggle Titanic Disaster
- Kubeflow Functionality – Kale, Katib
- Enterprise Kubeflow Skills – Kale SDK
Q&A from the training
Below is a summary of some of the questions that popped into the Q&A box during the course. [Edited for readability and brevity.]
For this course do I need to know how Kubernetes work to get an Idea of how kubeflow works?
A basic understanding of cloud-native architectures and Kubernetes concepts like pods, controllers, nodes, container images, and volumes is very helpful. A good starting point is the official Kubernetes docs to get a handle on basic concepts.
Is there a built-in versioning for the Notebooks in Kubeflow?
If you deployed Kubeflow via Arrikto’s Kubeflow as a Service or its Enterprise Kubeflow distribution, yes!

Are the RStudio and VSccode also supported in the open source Kubeflow project?
Yes. RStudio, Visual Studio Code and JupyterLab are all supported notebook types.
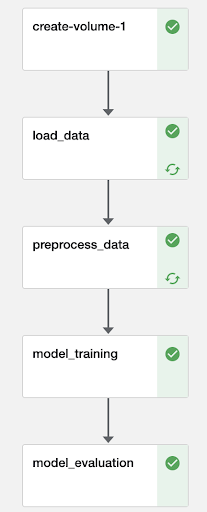
Do Kubeflow Pipelines support caching?
Yes! Caching helps to reduce costs by skipping computations that were completed in a previous pipeline run. When a pipeline runs, it checks to see whether an execution exists with the interface of each pipeline task.
Does Kubeflow integrate with Spark?
Yes. Here’s a talk from the Kubeflow and MLOps Meetup that covered this topic in detail.