

On Thursday we hosted the third course in the FREE “ Introduction to Kubeflow” training and certification series. This course focused on Kubeflow Notebooks, specifically JupyterLabs. In this blog post we’ll recap some highlights from the class, plus give a summary of the Q&A. Ok, let’s dig in.
Congratulations to Mark-Felix Müller!
The first person to earn the “Notebooks” certificate at the conclusion of the course was Mark-Felix Müller. Well done!
What topics were covered in the course?
This initial course aimed to get data scientists and DevOps engineers with little or no experience familiar with the fundamentals of how Kubeflow Notebooks work, how to navigate them and turn them into Pipelines using Kaggle and Udacity-based examples.
- Kubeflow Fundamentals Review
- Notebook Basics
- Getting Started with Kubeflow Notebooks
- Working with JupyterLab Notebooks
- Jupyter Example: Titanic Disaster
- Jupyter Example: Dog Breed Identification
- Course Review
What did I miss?
Here’s a short teaser from the 90 minute training. In this video we walk you through the Titanic Disaster example Notebook and convert it into a Pipeline.
Missed the Jan 13 Kubeflow Notebooks training?
If you were unable to join us last week, but would still like to attend a future training, the next “Kubeflow Notebook” training is happening on March 2, 2022. You can register directly on Zoom here.
Additional FREE upcoming workshops and trainings
We have a ton of workshops and trainings coming up in the next few months. Here’s a sample:
- Jan 27 – Intro to Kubeflow: Fundamentals Training and Certification
- Feb 9 – Notebooks & Pipelines: Getting Started with the Kaggle Titanic Disaster
- Feb 16 – Intro to Kubeflow: Fundamentals Training and Certification
- Feb 23 – Notebooks & Pipelines: The Udacity Dog Breed Classification Computer Vision Example
- Mar 2 – Intro to Kubeflow: Jupyter Notebooks Training and Certification
- Mar 9 – Notebooks & Pipelines: Kaggle Covid-19 OpenVaccine Machine Learning Example
- Mar 16 – Intro to Kubeflow: Pipelines Training and Certification
- Mar 23 – Notebooks & Pipelines: Kaggle Blue Book for Bulldozers Machine Learning Example
- Mar 30 – Intro to Kubeflow: Kale and Katib Training and Certification
Q&A from the training
Below is a summary of some of the questions that popped into the Q&A box during the course. [Edited for readability and brevity.]
Is there a recording for the first course in the series, “Kubeflow Fundamentals?”
Yes. You have two options here, depending on how you want to work the course.
- On-demand: Check out the course on Udemy.
Where can I get the demos for the Notebooks course?
You can find the complete playlist of demos for the Notebook course here. Lecture videos should be live in a week.
How is Kubeflow different from Istio?
In a nutshell, Istio is a service mesh popular with microservices architectures that run on top of Kubernetes. You can think of Kubeflow as an MLOps platform with a microservices-based architecture that runs on top of Kubernetes. As a result, Kubeflow ships with Istio in order to provide many of its default security features.
In regards to Kubeflow pipelines, if there are several cells for the same pipeline step, do they individually need to be assigned with Kale? As a follow-up, do they also each need to be assigned dependencies?
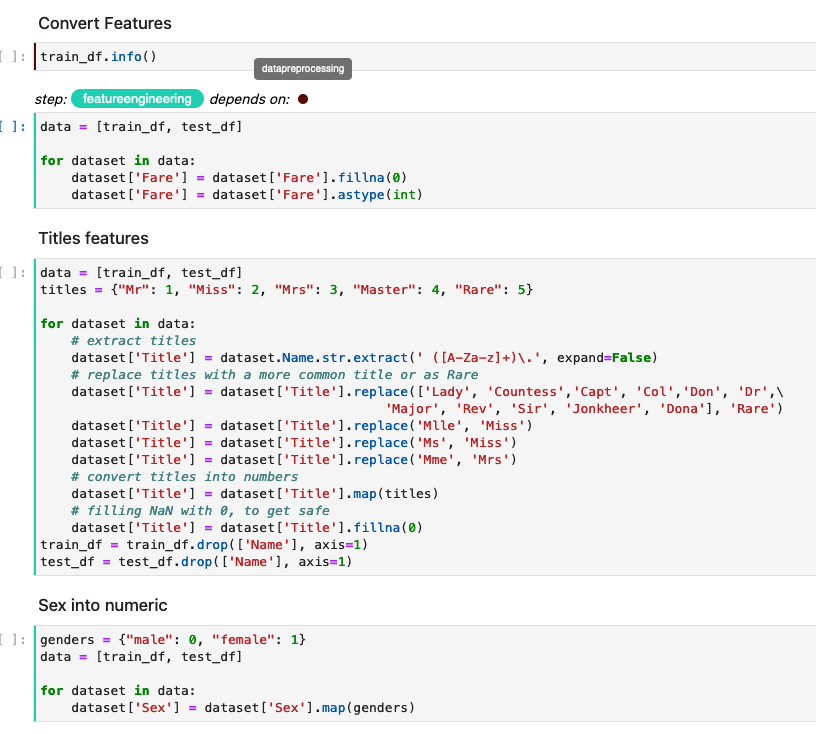
Let’s use the screenshot above from the Titanic Disaster Notebook we used in the course, to illustrate a few points.
- Notice that we have a step called
featureengineeringwhich Kale has labeled in an aqua color - Within the
featureengineeringstep we have multiple cells where inside of them some feature engineering operations are being performed - Notice that the entire step (which includes the cells inside the step) have the
dataengineeringstep as a dependency. (You can see the dependency labeled in the grey colored text tip and brown dot next to “depends on”) - Note that if you don’t define a new annotation for a cell, Kale will by default consider that cell as being a part of the previous step, so there is no need for manual annotation of every single step. Cells will be marked with the corresponding color on the left, as per the above screenshot.
How can Kale help turn my model into a Pipeline after I have developed it using JupyterLabs?
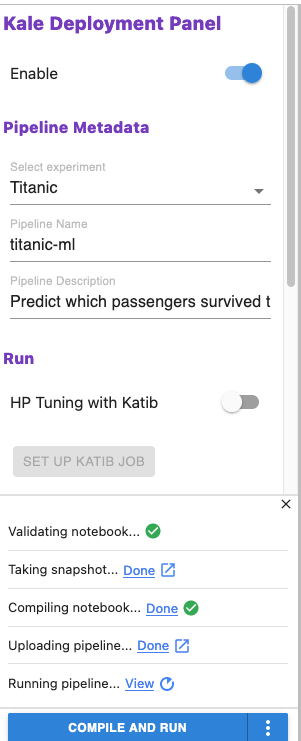
In the screenshot above, you can see that when the Kale JupyterLab extension is enabled, you just need to “point and click” to deliver the following “post model development” capabilities in Kubeflow:
- Validate the Notebook
- Take a snapshot
- Compile the Notebook
- Upload the Pipeline
- Run the Pipeline
- Perform Hyperparameter Tuning via Katib
- Serve the best model
Is it possible to implement multiple iterations of transfer-learning/fine-tuning through a Pipeline and obtain intermediate results?
Yes, this is possible. You may also want to check out KFP’s conditionals and looping features.
Can the data processing stage of a Pipeline use Spark?
Yes. Many folks have set up Kubeflow to call Spark jobs. Check out this talk, “Orchestrating Apache Spark with Kubeflow on Kubernetes” from one of the recent Kubeflow Meetups.
Which version of Kubeflow and Katib are you using for this tutorial?
When I shot the demos I was using Kubeflow 1.3. In looking at Kubeflow’s Manifests page on GitHub, the Katib version would be v0.12.0.
Our team has a Sr. Data Engineer, Jr. Data Engineer, Sr. Data Scientist and Jr. Data Scientist. How can teams collaborate while using Kubeflow? Can multiple users contribute/commit to a single notebook?
Yes, they can if they are part of the same shared namespace on Kubernetes. In general you can have individuals be part of both their own, private namespace and shared namespaces, which they share with others. For advanced workflows on Enterprise Kubeflow, we use Rok Registry for users to be able to share across namespaces as well, or across completely different clusters, cloning the work of others and continuing from there.