

Congratulations to the Kubeflow community and especially those in the KFServing working group on releasing KFServing 0.6 last week. If you are fairly new to Kubeflow or how development of the project is organized, here’s a quick primer.
Kubeflow Working Groups
The Kubeflow project is comprised of multiple technologies that when combined deliver a machine learning platform. For the sake of manageability, the Kubeflow project has been broken down into seven working groups with associated GitHub repositories. This makes it easier to develop, document and release specific building blocks of functionality.
These working groups include:
- AutoML
- Deployment
- Manifests
- Notebooks
- Pipelines
- Serving
- Training
What is KFServing?
KFServing (currently in Beta) enables serverless inferencing on Kubernetes and delivers high performance and abstraction interfaces for machine learning frameworks like TensorFlow, XGBoost, scikit-learn, PyTorch, and ONNX.
For example:
- KFServing provides a Kubernetes Custom Resource Definition (think extensions of the Kubernetes API) for serving machine learning models on frameworks like those referenced previously.
- KFServing minimizes the complexity inherent to production-grade machine learning deployments. It tackles challenges like autoscaling, networking, health checking, and server configuration by exploiting features like GPU autoscaling, scale to zero, and canary rollouts.
- KFServing provides prediction, pre-processing, post-processing and explainability, radically simplifying your machine learning inference server.
Check out the KFServing docs for more information.
What’s New in this Release
This new release included 18 new features, 13 fixes, 1 change and 12 Docs/developer experience fixes. Here’s some of the highlights:
Triton/SKLearn/XGBoost enabled in MMS
[#1470] – This merge allows custom model servers to work with Multi Model Serving.KFServing Web UI
[#1328, #1512, #1504] – These merges introduce a web app for managing InferenceService CRs.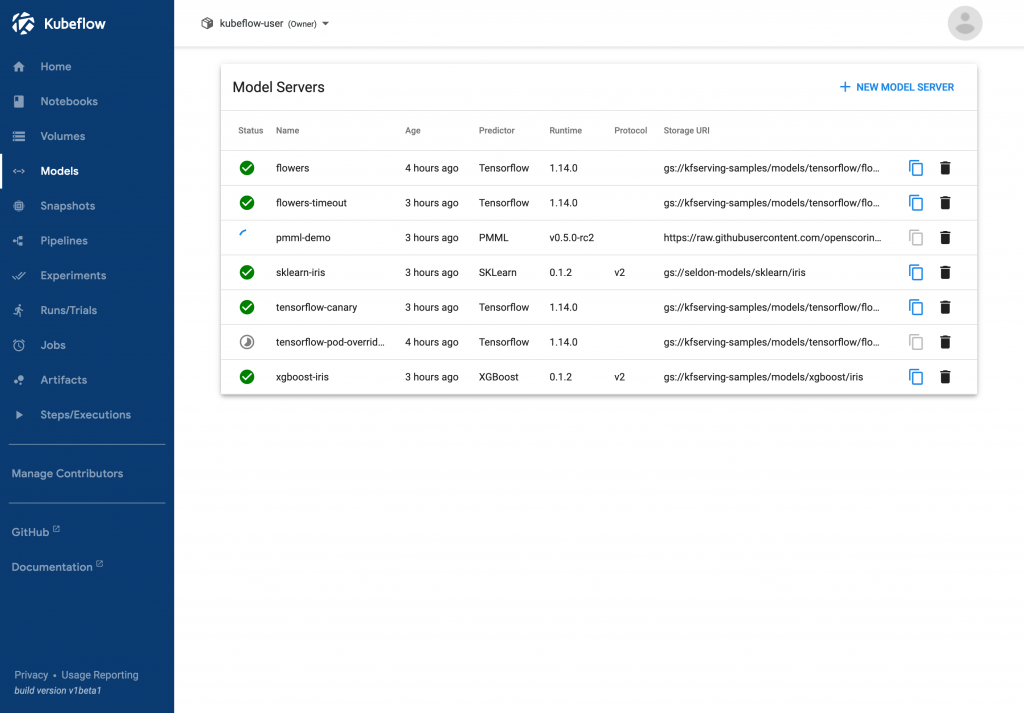
Add Paddle Predictor
[#1615] – This merge makes it easy for Paddle users (an open source deep learning platform) to now use KFServing to serve Paddle models.
Upgrade torchserve-kfs version
[#1649] – This merge upgrades TorchServe (a flexible and user friendly tool for serving PyTorch models) to 0.4.0
Improve PMMLServer predict performance
[#1405] – This merge was aimed at improving the PMMLServer (Predictive Modelling Markup Language) performance by doing three things:
- Replace pypmml to jpmml-evaluator-python
- Improve the documentation of PMMLServer
- Humanize PMML Predict results
Change storage-init to use boto3
[#1472] – This merge swapped out minio for the boto3 library in the storage-initializer. This was done primarily to allow the use of IAM Roles for Service Accounts for AWS users. Finally, it also changed the storage tests to mock boto3 instead of minio.
Parallel inference support
[#1637] – This merge uses RayServe’s (a scalable model-serving library built on Ray) Python ServeHandle APIs to scale up the model inference and offload the heavy computation to RayServe.
Add Feast Example
[#1647] – This merge added a transformer example to show how to augment inputs with features from a Feast (an open source feature store for machine learning) online feature store as part of preprocessing.
You can check out details on all the big fixes, changes and Doc improvements in the official KFServing 0.6.0 release notes on GitHub.
About Arrikto
At Arrikto, we are active members of the Kubeflow community having made significant contributions to the latest 1.3 release. Our projects/products include:
- MiniKF is a production-ready, local Kubeflow deployment that installs in minutes, and understands how to downscale your infrastructure
- Enterprise Kubeflow (EKF) is a complete machine learning operations platform that simplifies, accelerates, and secures the machine learning model development life cycle with Kubeflow.
- Rok is a data management solution for Kubeflow. Rok’s built-in Kubeflow integration simplifies operations and increases performance, while enabling data versioning, packaging, and secure sharing across teams and cloud boundaries.
- Kale is a workflow tool for Kubeflow, which orchestrates all of Kubeflow’s components seamlessly..